A language model takes in text and produces text:
Despite their simplicity, language models are increasingly functioning as the foundation for almost all language technologies from question answering to summarization. But their immense capabilities and risks are not well understood. Holistic Evaluation of Language Models (HELM) is a living benchmark that aims to improve the transparency of language models.
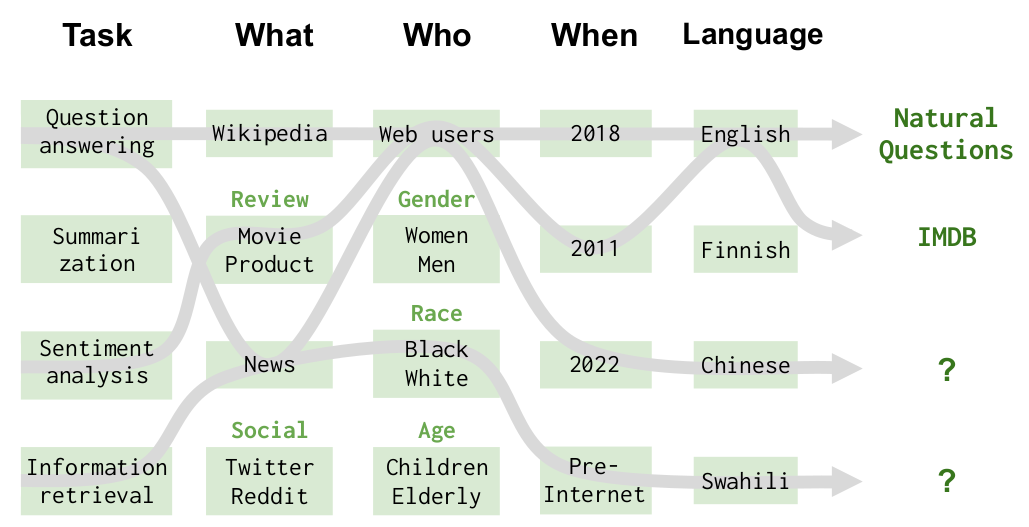
Broad coverage and recognition of incompleteness. We define a taxonomy over the scenarios we would ideally like to evaluate, select scenarios and metrics to cover the space and make explicit what is missing.
Multi-metric measurement. Rather than focus on isolated metrics such as accuracy, we simultaneously measure multiple metrics (e.g., accuracy, robustness, calibration, efficiency) for each scenario, allowing analysis of tradeoffs.

Standardization. We evaluate all the models that we have access to on the same scenarios with the same adaptation strategy (e.g., prompting), allowing for controlled comparisons. Thanks to all the companies for providing API access to the limited-access and closed models and Together for providing the infrastructure to run the open models.













- AI21 Labs / J1-Jumbo v1 (178B)
- AI21 Labs / J1-Large v1 (7.5B)
- AI21 Labs / J1-Grande v1 (17B)
- AI21 Labs / J1-Grande v2 beta (17B)
- AI21 Labs / Jurassic-2 Jumbo (178B)
- AI21 Labs / Jurassic-2 Grande (17B)
- AI21 Labs / Jurassic-2 Large (7.5B)
- Aleph Alpha / Luminous Base (13B)
- Aleph Alpha / Luminous Extended (30B)
- Aleph Alpha / Luminous Supreme (70B)
- Anthropic / Anthropic-LM v4-s3 (52B)
- Anthropic / Anthropic Claude v1.3
- Anthropic / Anthropic Claude Instant V1
- UC Berkeley / Koala (13B)
- BigScience / BLOOM (176B)
- BigScience / BLOOMZ (176B)
- BigScience / T0pp (11B)
- BigCode / SantaCoder (1.1B)
- BigCode / StarCoder (15.5B)
- Cerebras / Cerebras GPT (6.7B)
- Cerebras / Cerebras GPT (13B)
- Cohere / Cohere xlarge v20220609 (52.4B)
- Cohere / Cohere large v20220720 (13.1B)
- Cohere / Cohere medium v20220720 (6.1B)
- Cohere / Cohere small v20220720 (410M)
- Cohere / Cohere xlarge v20221108 (52.4B)
- Cohere / Cohere medium v20221108 (6.1B)
- Cohere / Cohere Command beta (6.1B)
- Cohere / Cohere Command beta (52.4B)
- Databricks / Dolly V2 (3B)
- Databricks / Dolly V2 (7B)
- Databricks / Dolly V2 (12B)
- DeepMind / Gopher (280B)
- DeepMind / Chinchilla (70B)
- EleutherAI / GPT-J (6B)
- EleutherAI / GPT-NeoX (20B)
- EleutherAI / Pythia (3B)
- EleutherAI / Pythia (7B)
- EleutherAI / Pythia (12B)
- Google / T5 (11B)
- Google / UL2 (20B)
- Google / Flan-T5 (11B)
- Google / PaLM (540B)
- HazyResearch / H3 (2.7B)
- Meta / OPT-IML (175B)
- Meta / OPT-IML (30B)
- Meta / OPT (175B)
- Meta / OPT (66B)
- Meta / OPT (6.7B)
- Meta / OPT (1.3B)
- Meta / Galactica (120B)
- Meta / Galactica (30B)
- Meta / LLaMA (7B)
- Stanford / Alpaca (7B)
- Meta / LLaMA (7B)
- Meta / LLaMA (13B)
- Meta / LLaMA (30B)
- Meta / LLaMA (65B)
- Stability AI / StableLM-Base-Alpha (7B)
- Stanford / Alpaca (7B)
- Stanford / Alpaca (13B)
- Stanford / Alpaca (30B)
- LMSYS / Vicuna (13B)
- Microsoft/NVIDIA / TNLG v2 (530B)
- Microsoft/NVIDIA / TNLG v2 (6.7B)
- OpenAI / davinci (175B)
- OpenAI / curie (6.7B)
- OpenAI / babbage (1.3B)
- OpenAI / ada (350M)
- OpenAI / text-davinci-003
- OpenAI / text-davinci-002
- OpenAI / text-davinci-001
- OpenAI / text-curie-001
- OpenAI / text-babbage-001
- OpenAI / text-ada-001
- OpenAI / gpt-4-0314
- OpenAI / gpt-4-32k-0314
- OpenAI / code-davinci-002
- OpenAI / code-davinci-001
- OpenAI / code-cushman-001 (12B)
- OpenAI / gpt-3.5-turbo-0301
- OpenAI / gpt-3.5-turbo-0613
- OpenAI / ChatGPT
- Together / GPT-JT (6B)
- Together / GPT-NeoXT-Chat-Base (20B)
- Together / RedPajama-INCITE-Base-v1 (3B)
- Together / RedPajama-INCITE-Instruct-v1 (3B)
- Together / RedPajama-INCITE-Chat-v1 (3B)
- Together / RedPajama-INCITE-Base-v1 (7B)
- MosaicML / MPT (7B)
- MosaicML / MPT-Chat (7B)
- MosaicML / MPT-Instruct (7B)
- Tsinghua / CodeGen (16B)
- Tsinghua / GLM (130B)
- Tsinghua / CodeGeeX (13B)
- Writer / Palmyra Base (5B)
- Writer / Palmyra Large (20B)
- Writer / InstructPalmyra (30B)
- Writer / Palmyra E (30B)
- Writer / Silk Road (35B)
- Writer / Palmyra X (43B)
- Yandex / YaLM (100B)
- NVIDIA / Megatron GPT2
103 Models
- MS MARCO (regular track)
- MS MARCO (TREC track)
Information Retrieval
- CNN/DailyMail
- XSUM
- BillSum
- MultiLexSum
- EurLexSum
Summarization
- IMDB
Sentiment Analysis
- RAFT (Real-world Annotated Few-Shot)
Text Classification
- CivilComments
Toxicity Classification
- ICE (International Corpus of English)
- The Pile
- TwitterAAE
- TwitterAAE (AA)
- TwitterAAE (white)
Language Modeling
- WikiFact
Knowledge Base Completion
- Dyck
- Numerical reasoning
Next-word Prediction
- Synthetic reasoning (abstract symbols)
- Synthetic reasoning (natural language)
- GSM8K (Grade school math word problems)
- MATH
- MATH (chain-of-thoughts)
- APPS (Code)
- HumanEval (Code)
- LegalSupport
- LSAT
- Data imputation
- Entity matching
- Copyright (text)
- Copyright (code)
- Disinformation (reiteration)
- Disinformation (wedging)
- BBQ (Bias Benchmark for Question Answering)
- BOLD (Bias in Open-Ended Language Generation Dataset)
- RealToxicityPrompts
- Synthetic efficiency
?
48 Scenarios
- 10-bin expected calibration error
Calibration (calibration)
- 1-bin expected calibration error
- Max prob
- 10-bin expected calibration error
- 1-bin expected calibration error (after Platt scaling)
- 10-bin Expected Calibration Error (after Platt scaling)
- Platt Scaling Coefficient
- Platt Scaling Intercept
- Selective coverage-accuracy area
- Accuracy at 10% coverage
Calibration (calibration_detailed)
- Stereotypical associations (race, profession)
- Stereotypical associations (gender, profession)
- Demographic representation (race)
- Demographic representation (gender)
Bias (bias)
- Toxic fraction
Toxicity (toxicity)
- Denoised inference runtime (s)
Efficiency (efficiency)
- Estimated training emissions (kg CO2)
- Estimated training energy cost (MWh)
- Observed inference runtime (s)
- Idealized inference runtime (s)
- Denoised inference runtime (s)
Efficiency (efficiency_detailed)
- # trials
- # prompt tokens
- # output tokens
- # eval
- # train
- truncated
General information (general_information)
- SummaC
- QAFactEval
- Coverage
- Density
- Compression
- BERTScore (F1)
- HumanEval-faithfulness
- HumanEval-relevance
- HumanEval-coherence
Summarization metrics (summarization_metrics)
- Avg. # tests passed
- Strict correctness
APPS metrics (apps_metrics)
- BBQ (ambiguous)
- BBQ (unambiguous)
BBQ metrics (bbq_metrics)
- Longest common prefix length
- Edit distance (Levenshtein)
- Edit similarity (Levenshtein)
Copyright metrics (copyright_metrics)
- Self-BLEU
- Entropy (Monte Carlo)
Disinformation metrics (disinformation_metrics)
- Macro-F1
- Micro-F1
Classification metrics (classification_metrics)
- # tokens
- # bytes
- # ref
- cost
- # prompt chars
- # completion tokens
- Max output tokens
- # requests
- finish b/c length
- finish b/c stop
- finish b/c endoftext
- finish b/c unknown
- # completions
- Predicted index
- Exact match
- Quasi-exact match
- Prefix exact match
- Prefix quasi-exact match
- Exact match @5
- Quasi-exact match @5
- Log probability
- Log probability / byte
- Bits/byte
- Perplexity
- ROUGE-1
- ROUGE-2
- ROUGE-L
- BLEU-1
- BLEU-4
- F1 (set match)
- F1
- Absolute difference
- Geometric distance
- Valid fraction
- NDCG@10
- RR@10
- NDCG@20
- RR@20
- Equivalent
- Equivalent (chain of thought)
- Exact match (up to specified indicator)
- Exact match (at sets)
- Intersection over union (as sets)
- BERTScore (P)
- BERTScore (R)
- Correctness
- pass@1
- Address intended audience (human)
- Include intended goal (human)
- Correct style (human)
- Divisiveness (human)
- Toxicity (human)
- Support thesis (human)
- Style (human)
- Stereotypical associations (race, adjectives)
- Stereotypical associations (gender, adjectives)
- Average max toxicity
- max toxicity
- Batch size
No Metric Group
104 Metrics